
grep,awk,sed与正则表达式学习
grep
grep 命令用于查找文件里符合条件的字符串,即查找内容包含制定的范本样式的文件,如果发现某文件的内容符合制定的范式样本,则会把含有范式样本的那一行显示出来
语法 grep 选项 需要捕获的文字 目标文件,比如从 /etc/passwd 中查找tcpdump相关的信息 grep tcpdump /etc/passwd
选项主要使用的有:
-A显示捕获行之后的行-B显示捕获行之前的行-C显示捕获行前后的行-c显示符合条件的行数-i忽略大小写-n输出符合条件文件所在行号-v不包含关键字的行
比如:过滤以#开头的行 grep -v '^#' /etc/ssh/sshd_config
过滤以#开头的行和空行 grep -v '^#' /etc/ssh/sshd_config | grep -v '^$'
正则表达式
在上面最后的例子中, '^#' 和 '^$' 都是正则表达式的匹配法
正则表达式(regular expression) 描述了一种字符串的匹配模式,可以用来检测一个串是否含有某种子串,将匹配的子串替换或者从某个串中取出符合某个条件的子串等
一些正则表达式的测试网站:
https://regex101.com/
https://tool.oschina.net/regex/
匹配普通字符
普通字符包括没有显示制定为元字符的所有可打印和不可打印字符,包括所有大小写字母,数字,标点符号和一些其他符号
[] 中的字符就是要匹配的字符,[aeiou] 单个匹配中括号中的这几个字符[^aeiou] 单个匹配不是中括号中这几个的其他字符[a-z] 匹配a到z的所有字母[\s] 匹配所有空白字符,包括换行,制表,换页等[\S] 匹配非空白符[.] 匹配除换行符之外的任意单个字符[\w] 匹配字母数组下划线
\f 匹配一个换页符\n 匹配一个换行符\r 匹配一个回车符\t 匹配一个制表符\v 匹配一个垂直制表符
特殊字符

限定符

定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如^*之类的表达式。

选择
使用圆括号 () 将所有选项括起来,相邻的选项之间使用 | 来分隔,() 表示捕获分组,() 会把每个分组里的匹配值保存起来,多个匹配值可以通过数字来索引
1 | n="123456runoob123runoob456".match(/([1-9])([a-z]+)/g) |

grep 与 正则结合
前面使用 gerp -v ^$ 这类正则表达式是grep自身支持的,如果想要使用完整的正则语法,可以使用 grep -E 或者写作 egrep
sed 编辑器
sed概述
Sed 是一个流处理编辑器,它能帮助我们自动处理文件,分析日志文件,修改配置文件等,是一个 “非交互式的” 面向字符流的编辑器,能同时处理多个文件多行的内容
- 可以不对原文件改动,把整个文件输出到屏幕
- 可以把匹配到的内容输出到屏幕上
- 还可以对原文件改动,但是不会在屏幕上返回结果
sed处理流程
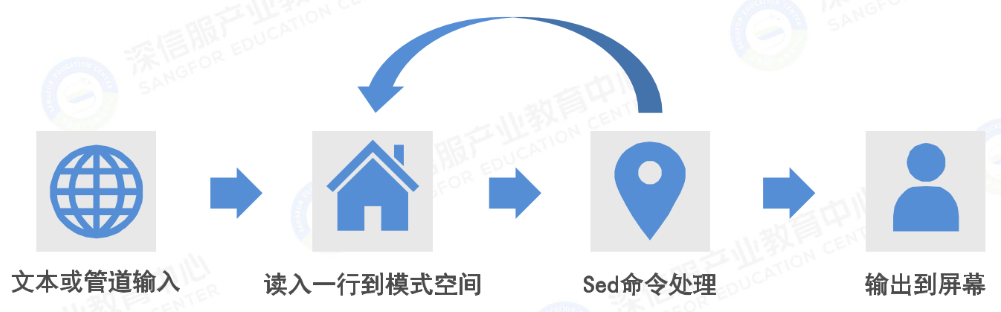
sed参数说明
sed [-hnV][-e <script>][-f <script文件>][文本文件]
-e<script>或--ecpression=<script>以选项中指定的script来处理输入的文本文件-f<script文件>或--file=<script文件>以选项中指定的script文件来处理输入的文本-h显示帮助-n仅显示script处理后的结果-V显示版本信息
sed动作可以理解为操作
a:新增,a的后面可以接字符串,新增字符串会在目前的下一行c:取代,c的后面可以接字符串,这些字符串取代n1,n2之间的行d:删除i:插入,i的后面可以接字符串,新增的字符串会在目前行的上一行p:打印,将某个选择的数据先输出,通常p会与参数sed -n 一起运行s:替换,可以直接进行替换,通常这个s的动作可以搭配正则表示
sed示例
有如下文件 test.txt
1 | Hello 11111 |
在文件中查找包含2222的行
1
cat test.txt | sed -n '/2222/p'

在文件中添加第三行,内容为 hello
1
sed -e '2a hello' test.txt
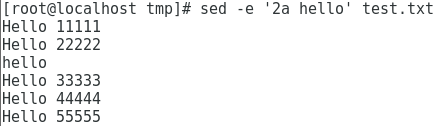
删除第2行到第4行
1
sed -e '2,4d' test.txt

删除包含222222的行
1
sed -e '/22222/d' test.txt
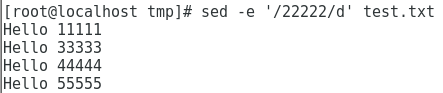
把 1-3行替换为 hahaha
1
sed -e '1,3c hahaha' test.txt

查找替换,将文本中的Hello换成haha
1
sed -e 's\Hello\haha\g' test.txt

修改文件
前面的操作,知识在屏幕上按照要求输出了内容,而文件本身没有改变,sed也可以用于文件自身的修改,但这样操作非常危险,有可能误操作将文件改坏,所以我们必须有把握才能这么做
在什么的操作中,结合 -i 就可以修改文件了,比如
1 | sed -i -e '2a hello' test.txt |
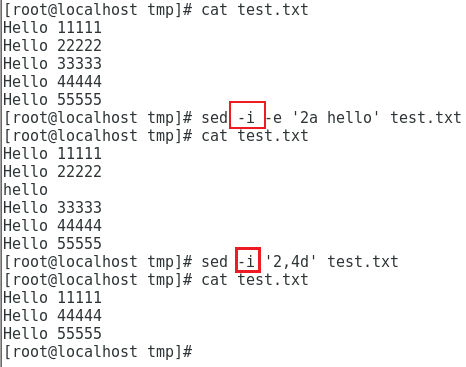
awk
awk简介
awk 是一种编程语言,用于在 linux/unix 下对文本和数据进行处理,支持用户自定义函数和动态正则表达式的功能,是 linux/unix 下的一个强大编程工具
awk一次处理一行内容,对每行可以切片处理,空格和制表符为默认分隔符将每行切片,切开的部分再进行各种分析处理
awk格式
命令行格式
awk [选项参数] 'script' var=value file(s)
script组成: pattern {awk操作命令}
- pattern:正则表达式;逻辑判断式
- awk操作命令:内置函数 print(),printf(),getline…;
- 控制命令:if(){..}else{..};while(){…}
扩展格式:BEGIN{print “start”}pattern{commands}END{print “END”} **
注意:加粗的部分在所有commands之前和之后**执行
awk内置参数
内置变量1:
$0表示整个当前行$1每行第一个字段- …
内置变量2;
NR每行的记录号,行号NF字段数量变量,字段总数FILENAME正在处理的文件名
awk示例
以
:分割,显示/etc/passwd 的第一列1
awk -F : '{print $1}' /etc/passwd

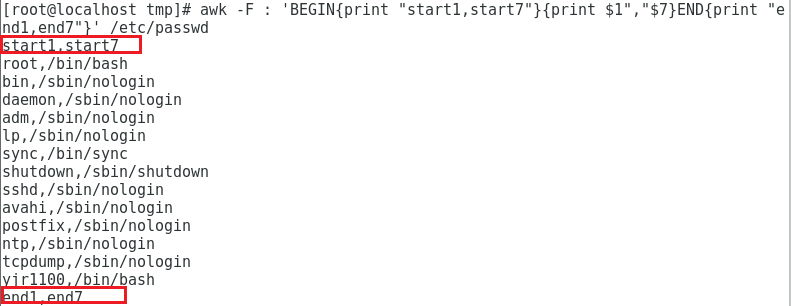
显示/etc/passwd的第一列和第七列,用逗号分隔显示,所有行开始前添加列名
start1,start71
awk -F : 'BEGIN{print "start1,start7"}{print $1","$7}END{print "end1,end7"}' /etc/passwd
匹配某段字符
1
awk -F : '$1 ~ /00/' /etc/passwd
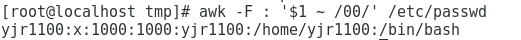
显示前五行的行号,列数,以及行内完整内容
1
head -n5 /etc/passwd | awk -F : '{print NR " " NF " " $0}'

条件匹配操作
1
awk -F : '$3=="0"' /etc/passwd
 这里操作符号可以用 `==`,`>`,`>=`,`<`,`<=`,`!=` 等,和数字比较时,将数字用双引号引起来表示字符串,不加引号表示数字
这里操作符号可以用 `==`,`>`,`>=`,`<`,`<=`,`!=` 等,和数字比较时,将数字用双引号引起来表示字符串,不加引号表示数字累加前四行用户的uid
1
head -n4 /etc/passwd | awk -F : '{(sum=sum+$3);print $0}END{print sum}'

流程控制
1
awk -F : '{if($1>"q"){print $1}else{print "-"}}' /etc/passwd
 也可以将上面的语句放在一个脚本中去调用,比如在`awkscript`这个文件中写入下面的脚本
使用下面的命令去调用
也可以将上面的语句放在一个脚本中去调用,比如在`awkscript`这个文件中写入下面的脚本
使用下面的命令去调用1
2
3
4
5
6
7
8{
if($1 > "q"){
print $1
}
else{
print "-"
}
}1
awk -F : -f awkscript /etc/passwd



